Recurrent Neural Networks, 줄여서 RNN의 대표 모델들 공부.
Introduction
RNN은 기본적으로 순차적 정보를 가지는 sequential data(ex. time-series data) 를 효과적으로 학습하기 위해 고안된 모델이다. 데이터의 종류를 구분하는 방법은 여러가지가 있지만, 아주 간단하게는 many OR one 으로 구분할 수 있다.

*[Figure 0] Sequential data and RNN
위와 같이 RNN이 풀 수 있는 문제는 다양하다
Short History
RNN 아이디어 자체는 1980년대 등장하여 근 30년간 조용히 연구되던 분야다. 기본 RNN을 계승하여 attention 기법, LSTM, GRU 등의 모델들이 차례로 등장하였고, 이 모델들의 성과는 그 당시 꽤 만족스러웠기에 Sequential data 하면 RNN을 통상적으로 사용해왔다. 특히 자연어 및 비디오/음성 데이터와 같이 순차적 성질을 가진 데이터의 경우 RNN 계열 모델을 사용하는 것이 당연했다.
Then in the following years (2015–16) came ResNet and Attention. One could then better understand that LSTM were a clever bypass technique. Also attention showed that MLP network could be replaced by averagingnetworks influenced by a context vector.
Reference - ‘The fall of RNN and LSTM’, 2018, Eugenio Culurciello
2017년 12월에 ‘Attention is all you need’ 라는 제목의 논문이 게재되었다. 논문은 기존 RNN 기반 알고리즘을 완전히 탈피하고, sequential data를 처리할 수 있는 새로운 모델 - Transformer를 제안했다. 물론 그 이전에도 attention 기법을 기존 모델에 적용하려는 시도 및 성과는 분명 있었으나, RNN의 틀을 벗어나지는 못했었다. 논문은 그 상식을 깨고, 제목처럼 attention’만’ 써도 순차 정보를 처리하기에 충분하며 심지어 더 좋기까지 하다는 내용을 발표한 것이다. 뿐만 아니라 이들이 소개한 Transformer는 기존 SOTA 모델들을 월등한 차이로 이기며 많은 NLP task에서 좋은 점수를 냈다. 이 논문을 기점으로 NLP 분야의 연구 방향이 확 바뀌었다고 볼 수 있을 것 같은데, 이 Transformer 공부를 위해 기존 RNN 기법부터 차근차근 정리 해보려 한다.
1. RNN
RNN은 n번째에 대한 output #n 을 생성하기 위해, 그에 상응하는 input #n 과 추가적으로 n-1번째 hidden state #n-1 를 전달하여 문장의 순차적 특성을 활용 및 보존한다.
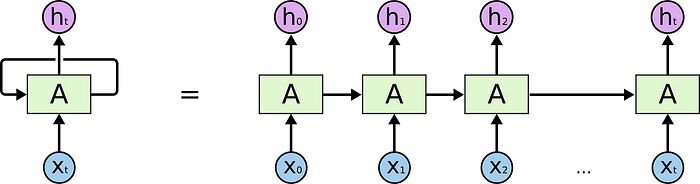
[Figure 1.1] RNN basic architecture
위는 RNN의 기본 구조를 잘 표현한 그림. 동작 방식은 대략 Input data의 순서대로,
1
2
3
4
5
1. input x_n을 n번째 cell에 입력
2. input x_n & hidden state_n-1 을 cell 가중치에 곱하여 예측 값인 output h_n 을 출력
3. hidden state_n 을 다음 n+1번째 cell에 전달
4. input x_n+1을 n+1번째 cell에 입력
5. ...반복... 입력 시퀀스가 끝날 때까지
보다시피 순차적인 input-output 방식에 hidden state라는 벡터가 추가되어 동작하는데, 이 hidden state 는 순차적으로 Input -> Output 계산을 해나갈 때 차례차례 전달되어 다음 연산시 함께 계산된다. n번째 input에게 이전 input(0부터 n-1번째)들의 정보를 전달하기 위함이다.
- Forward

*[Figure 1.2] RNN Forwarding Example
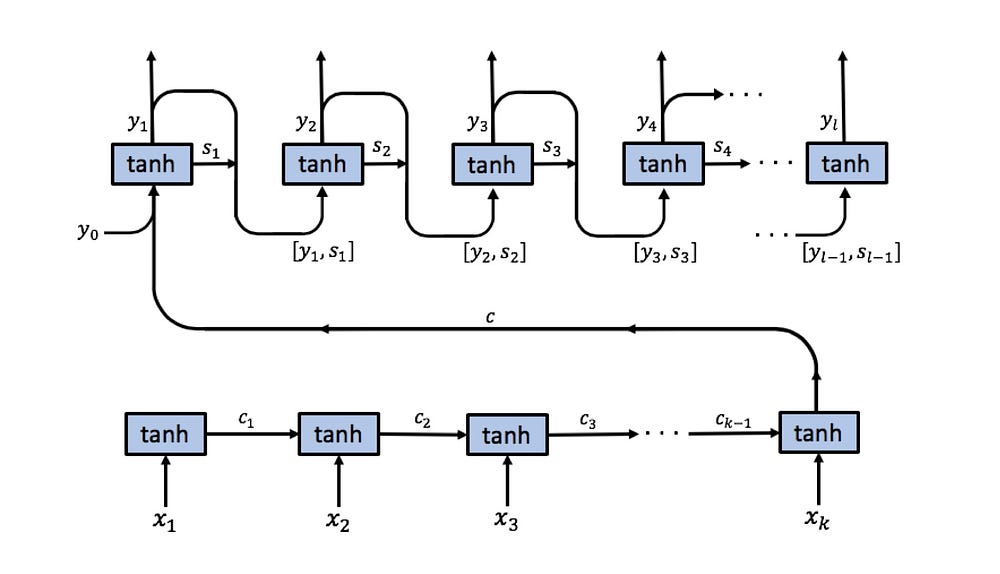
Forwarding 하는 과정을 조금 더 자세히 보자. 위 그림은 ‘hell’ 이라는 순차문자열을 input으로 하였을 때, 다음에 나올 문자를 ‘o’ 라고 예측하는 예시이다. 첫번째 순서인 ‘h’ 를 첫번째 cell에 푸쉬하고 hidden layer의 연산을 통해 다음에 나올만한 문자를 확률 값으로 나타낸다. 보면 마지막 행인 ‘o’ 4.1로 가장 확률이 높지만 사실 답은 2번째 초록 글씨로 볼드처리된 ‘e’인 것을 알 수 있다. 그러니 초록글씨 행은 강화되고 빨간 글씨 행들은 약화되도록 학습시킬 것이다. 두번째 문자인 ‘e’도 같은 방식으로 연산된 후 ‘o’를 1.2의 확률로 가장 높게 예측했다. 틀렸다. 이번에도 첫번째 했던 것과 똑같은 방식으로 학습 시킬 것이다. 하지만 이번부터는 hidden layer가 동작하고 있음을 주목해야 한다. 이번에 예측된 ‘o’는 앞서 계산하였던 ‘h’에 대한 정보를 전달 받아 input 인 ‘e’ 와 함께 연산된 결과이다. 다음 cell은 다음 input인 ‘l’ 과, 전달 받은 과거의 정보(h, e)가 담긴 hidden state를 함께 연산하여 다음 문자를 예측한다. 세번째는 잘 맞췄다. 이제 마지막, 실제 정답인 ‘o’를 예측해야 하는 마지막 cell 에게 각각 상응하는 가중치와 연산된 hidden state, input을 입력 받아 다음에 나올 문자에 대한 probability를 계산한다. (+ 위 예시는 teacher forcing을 적용한 예시. 모델이 틀린 답을 냈지만 다음 cell의 input에 target char를 넣어주고 있음.)
보통, 실제 input인 ‘hell’ 에 대해 진행한 세 번의 연산은 encoder라 하고, 마지막 실제 알고자 하는 결과에 대한 연산을 decoder라 한다. 이 예제는 many to one이기에 매우 간단해 보이는데, 만약 many to many 모델이면 실제 인풋이 끝나는 지점에서 hidden state에 가중치 W_hh를 곱해준다. 또한 decoder에서 input 대신 바로 이전 cell의 output을 input으로 사용한다.
![img]()
*[Figure 1.3] RNN many to many architecture
2. Attention Mechanism
위와 같은 RNN 구조의 가장 큰 한계점은 바로 Long-Term dependency 문제다. Long-term dependency는 문장이 길어질수록 비교적 초반부에 입력받은 input에 대한 정보를 손실하게 되는 현상을 말하는데, RNN에서 이 문제를 해결하고자 고안된 메커니즘 중 하나로 attention이 있다.

*[Figure 2.1] RNN with attention
베이직한 RNN 모델은 Encoder가 먼저 순차적으로 문장을 읽어가며 하나의 hidden state 값을 전달해 나갔으나, 문장이 길어지면 비교전 초반부의 내용이 희미해지는 문제가 있다.
-> 그렇다면, hidden state를 여러개 만들자!
베이직한 RNN 모델에서는 hidden state가 모든 input data를 거친 후 디코더의 시작 cell에 전달되기 때문에 input data의 앞 내용을 많이 잊어버린 상태일 수 밖에 없었다. 그렇기에 각 input에 대한 hidden state를 따로 저장해놓고 그 순서에 맞는 decoder cell에 전달해주자는 아이디어가 나온 것 같다. 이 방법으로 성능이 개선 되었다고는 하나, 개인적으로는 이게 attention이라는 단어와는 잘 안 맞는다는 생각이 들기도 한다. attention이라면 뭔가 주목을 해야 하는데, 이건 주목이라기 보단 그냥 초반부의 정보를 저장해놓고 활용하는 트릭인 것 같기도 하고…(내가 잘 이해한 게 맞나?)
3. LSTM(Long Short-term Memory)
Long-term dependency를 극복하고자 한 또다른 시도는, hidden state 계산을 업그레이드 시킨 LSTM 이다. LSTM은 기존 RNN 구조를 기반으로 하되, 이제 hidden state는 무작정 합성곱만 하는 것이 아니라, 기억해야 할 정보와 잊어버려도 될 정보들을 따로 계산하여 최대한 input 데이터의 핵심만 남기려 한다.

*[Figure 3.1 ~ 3.5] LSTM Architecture
전체 흐름은 기본 RNN과 동일하나, Cell state update는 크게 세가지 스텝으로 진행된다.
Forward
(1) Forget gate
먼저 현재 Cell-state 값을 업데이트 하기 위해 forget gate와 input gate를 각각 따로 거친다.
![img]()
forget gate의 수식은 위와 같다. 이전 Cell의 아웃풋(h_t-1)과 현재 인풋(x_t)를 forget layer의 Weight 및 bias 를 거쳐 시그모이드에 의해 0과 1 사이의 확률값으로 표현된다. 이렇게 표현된 값은 이전 아웃풋과 현재 인풋을 보고, 이전의 정보를 얼만큼 잊을 것인가? 를 정의한다고 볼 수 있다. 따라서 이 값은 이전 Cell state(C_t-1)과 연산한다.
(2) Cell-state 업데이트
![img]()
이제 현재 Cell-state를 실질적으로 업데이트 한다. 먼저 이전 아웃풋과 현재 인풋의 가중치 연산에 따라 얼마나 정보를 업데이트 할 것인지 확률값으로 나타내고(i_t), 또 다른 가중치 연산을 tanh 하여 -1 ~ 1 의 값으로 표현한 현재 Cell state의 추정치(C_t)를 구한다. 수식이 이해하기 쉽다.
![img]()
마지막으로 앞서 계산한 f_t 와 이전 Cell state 값을 연산하여 이전 정보를 어느 정도 담고, 현재 추정되는 Cell state의 값을 i_t를 통해 어느 정도 담아 현재 Cell-state값을 완성한다.
(3) Output 도출
![img]()
현재의 Cell state 를 구했다면 이제 아웃풋 값을 계산할 수 있다. 전과 비슷한 과정으로 아웃풋이 계산된다. (그림의 x 부호는 Hadamard product 연산)
matrix 연산부까지 구현한 코드
https://gist.github.com/karpathy/d4dee566867f8291f086




4. GRU(Gated Recurrent Unit)
LSTM의 발전된 형태로, 성능은 유지하면서 계산량을 확 줄인 셀 구조이다. 기존 forget, input, output gate를 update gate 와 reset gate로 변형하였다. 불필요한 계산을 줄여 보다 컴팩트해진 LSTM 모델이다.

*[Figure 4.1] GRU architecture
Last Update: 2019/07/30
References
http://colah.github.io/posts/2015-08-Understanding-LSTMs/