Abstract
Foley sound, audio content inserted synchronously with videos in post-production, plays a crucial role in the user experience of multimedia content. Recently, Foley sound synthesis has been actively studied, leveraging the advances in deep generative models. However, such works mainly focus on mimicking a particular sound class as a single event or a holistic context without temporal information of individual sources. We present T-Foley, a Temporal-event guided waveform generation model for Foley sound synthesis. T-Foley generates high-quality audio using two conditions: the sound class and the temporal event condition. The temporal event condition is implemented with Block-FiLM, a novel conditioning method derived from Temporal-FiLM. Our model achieves superior performances in both objective and subjective evaluation metrics and generates Foley sound that is well-synchronized to the temporal event condition. We particularly use vocal mimicking datasets paired with Foley sounds for the temporal event control, considering its intuitive usage in real-world application scenarios.
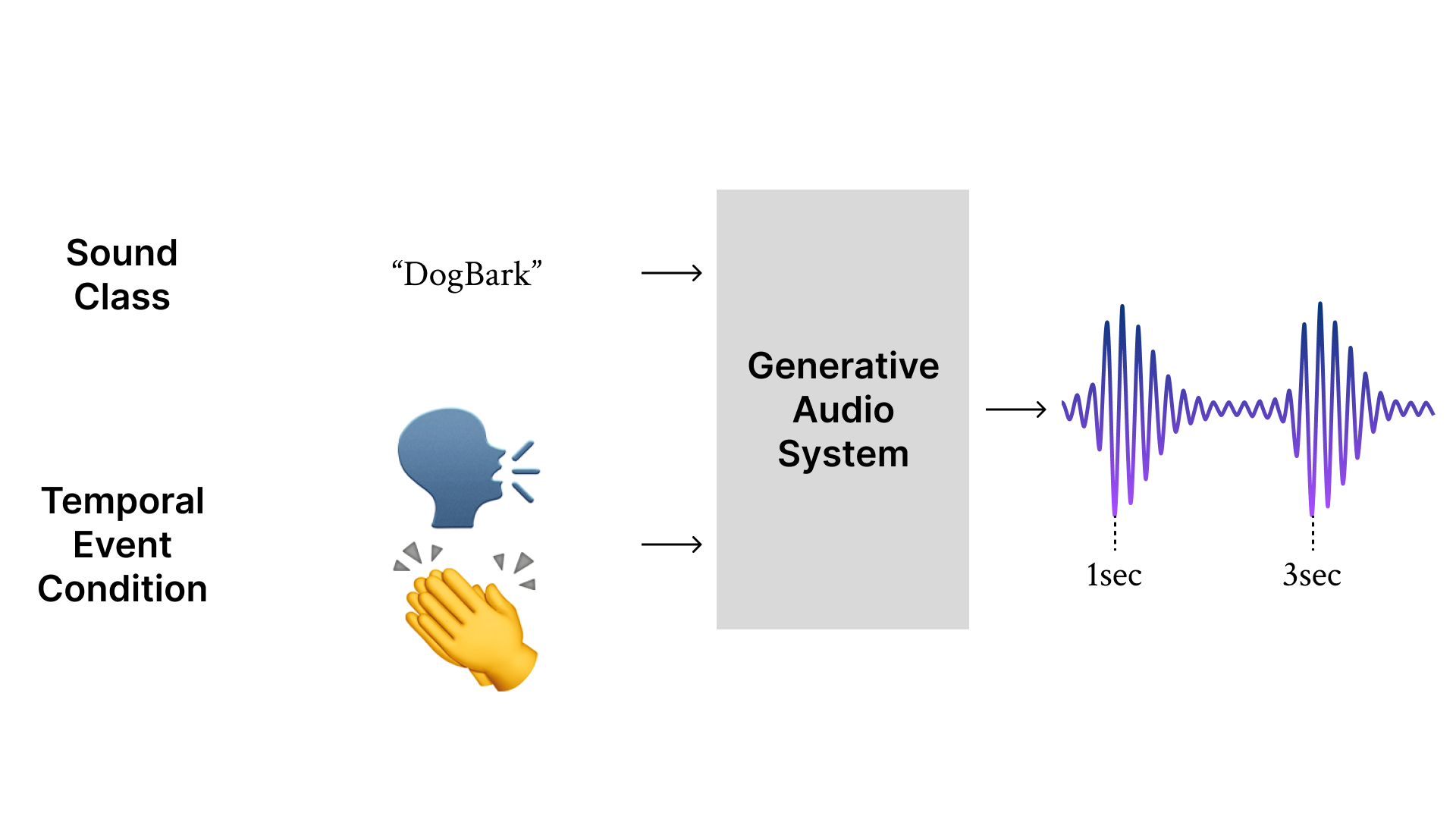
User Input Condition
Creating Foley sounds manually is challenging and labor-intensive work. Therefore, the ultimate goal of this study is automating the Foley sound synthesis to allow anyone to easily generate sounds. However, in real-world applications, directly inputting event timing features, such as power and RMS, is not straightforward for users. In this manner, receiving the audio that can serve as a reference of event timings and extracting its event timing features to use as sampling conditions would be more intuitive.
To demonstrate that T-Foley performs well in such use cases, we conducted experiments using various types of sound(e.g. clapping, voice) as timing condition references. We manually recorded target samples delivering the desired timing points and then these recorded sounds are used as event timing conditions to generate sounds in different categories.
1. Clap
When target sample, which indicate when the events should occur, is recorded by clapping.
2. Voice
| DogBark | GunShot | MovingMotorVehicle |
|---|---|---|
| Keyboard | Rain | Footstep |
The generated results demonstrated that our model has the ability to generate high-quality Foley sounds using even clapping sounds or human voicesas event timing features. Through this, we have confirmed the potential and practical applicability of this work.
(+) Vocal Imitating Dataset
To quantitatively evaluate T-foley in various voice samples, we assess our model using subsets of two vocal datasets that mimic foley sounds: VocalImitationSet and VocalSketch. We release the corresponding subsets: VocalImitationSet and VocalSketch.
| Vocal Condition | T-Foley | Mixed (L:Vocal, R:T-Foley) | |
|---|---|---|---|
| DogBark | |||
| Footstep | |||
| Gunshot | |||
| Keyboard | |||
| MovingMotorVehicle | |||
| Rain |
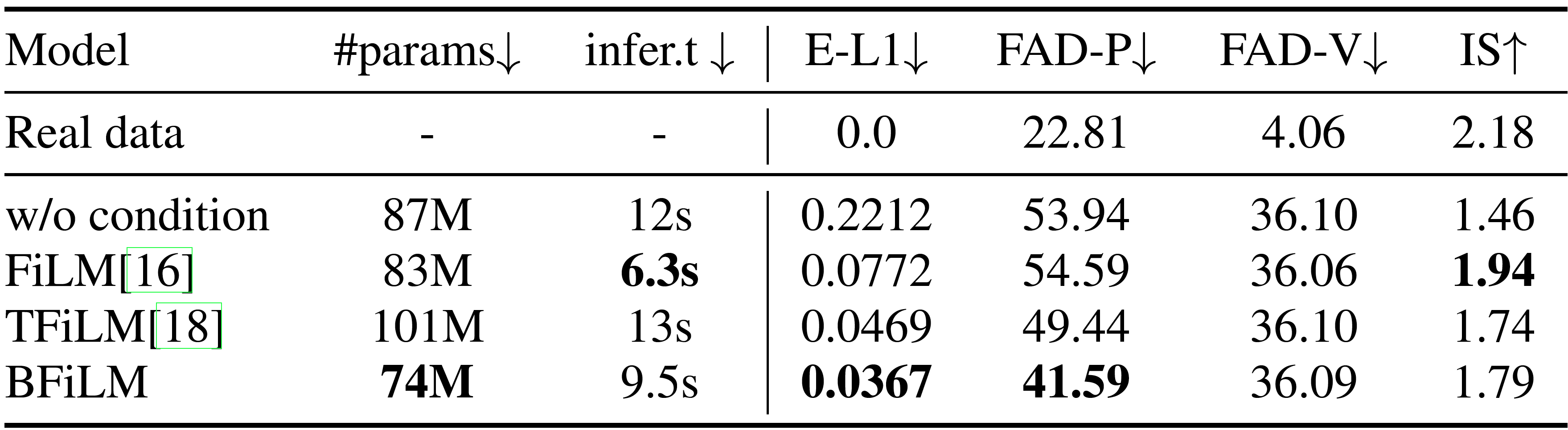
Temporal Event Conditioning Methods
Figure 1 and following demo samples contain the target samples, along with the corresponding 3 generated samples following each conditioning method. The first row is the sounds used to extract targeting event timing features. Subsequent rows are the generated results in different conditioning blocks (FiLM, TFiLM, and BFiLM). Columns for different sound categories (Gunshot, Footstep, and Keyboard)
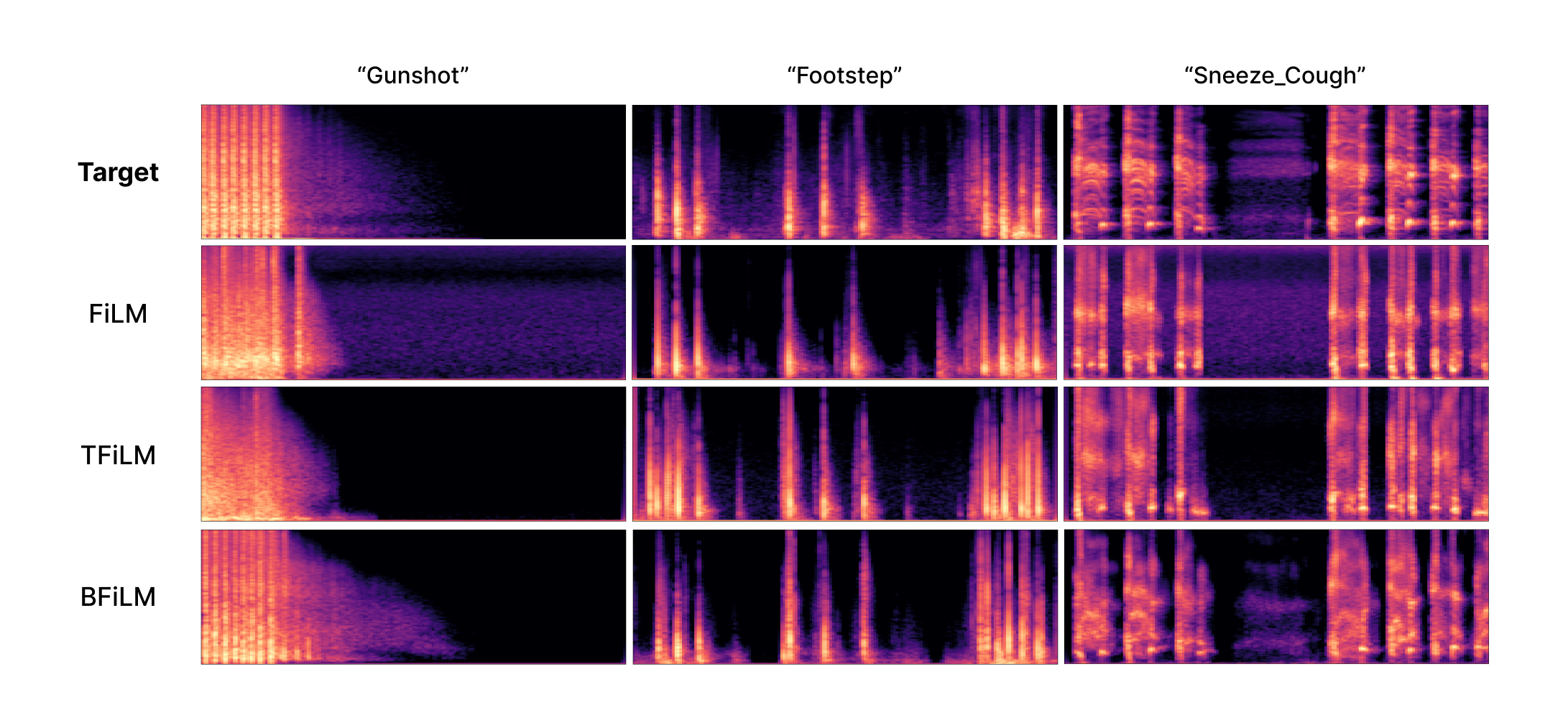
| GunShot | Footstep | Sneeze/Cough | |
|---|---|---|---|
| Target | |||
| FiLM | |||
| TFiLM | |||
| BFiLM |
Why T-Foley?
Generating foley sounds using temporal event conditions produces significantly more realistic outcomes compared to manual foley sound manipulation. We illustrate two specific applications. Firstly, envision a situation involving consecutive machine gunshots. Manually adjusting and joining individual gunshot sound snippets can result in an unnatural audio sequence. Conversely, employing T-Foley to concatenate temporal event conditions leads to a seamless and lifelike sound. Secondly, contemplate two scenarios: typing vigorously on a typewriter and softly pressing keys on a plastic keyboard. T-Foley can generate these sounds using identical temporal event features while varying the overall amplitude. It is important to note that the temporal event feature encloses information regarding sound timing and intensity.
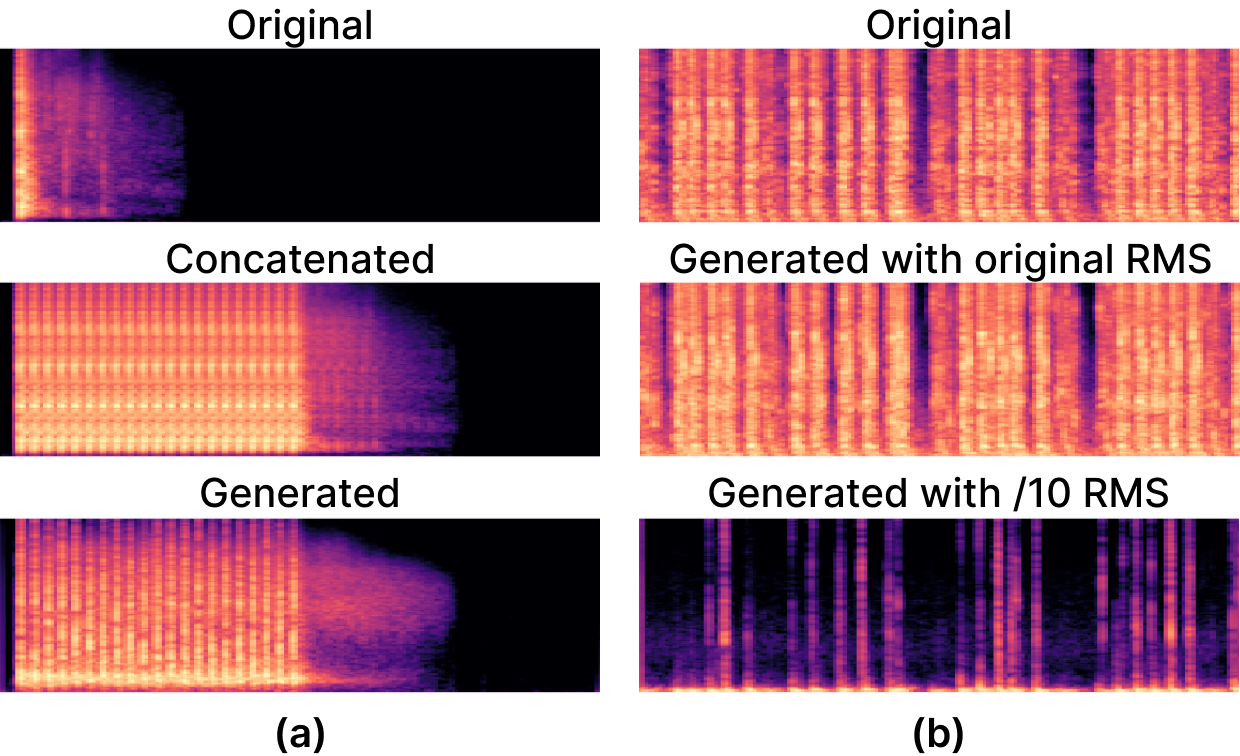
| Original | Concatenated | Generated | |
| (a) |
| Original | Generated with original RMS |
Generated with /10 RMS |
|
| (b) |